Making मनसा: a Nepali Programming Language

I've been working on and off on a Nepali programming language with my friends for the last few months. It's called मनसा (IAST: mansā) and I think it's ready for an alpha release. If you'd like to try the language out, visit mnsa.cc - the official website. You can play around with the language right in the browser without having to download anything, not even a Devanagari keyboard layout.
This post is a collection of random things I want to say about the language, including how the idea came about, the interesting things I learnt making the project, and the problems faced.
How it all started
In the sixth semester, we are required to submit a team project by the end of the term. Most teams in my class were making boring things, like hotel management systems, or polling websites. If you get to chose your own project, why not do something exciting and new? We settled on making a programming language. "Why not in Nepali?", I said, and after a long debate, we settled on building a Nepali programming language.
In the beginning, we thought a Nepali programming language wouldn't have any practical use at all. We thought that all this project would ever be is a novelty, a fun thing to play with and forget about, something like Brainfuck or Befunge. But as we continued to look into things to include in our proposal, we realized that a Nepali programming language might have a few very niche but very practical uses.
After some more deliberation, we decided that it had to be a compiled language, because that was the most difficult to make in terms of code, and the "coolest". It was exciting and somewhat uncertain because we don't have Compiler Construction classes in our syllabus, so we had basically zero idea on how we'd proceed. And we didn't know how to work with Nepali characters in the program. It was a great learning experience.
The language
The language is actually very tentative at this point and we're still refining it. You should be able to get the general idea of the syntax by the small example code below. If you don't, wait for the official documentation to be finished. It's in the works.
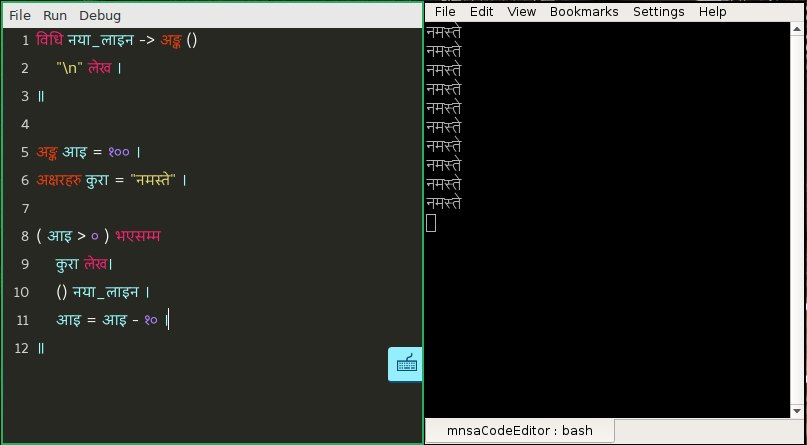
We have made a few changes to the conventional structure of a program statement to make it more expressive. For example, in function calls, the name of the function comes after the parameters, as verb comes at the end of sentence in Nepali. So "print Something" becomes "something लेख". We similarly modified other constructs such as conditionals and loops to fit into the Nepali grammar structure more. Technically, it is a very small change but it really does help make the programs more readable in Nepali. It was surprising how fluid the language becomes by changes so simple.
The compiler
The compiler was written in C++ completely from scratch. I didn't want to use lexer or parser generators because these tools hide the interesting and complicated details. That is a good thing if your goal is to make good, maintainable compilers but, as a student, I wanted to explore all the gory details and learn everything I could. I should mention here that the series of lectures by Alex Aiken is an amazing resource, and if you're planning on doing compilers too, you can at least skim through the videos to see the big picture.
I used Visual Studio Code to write C++ code this time. I actually started coding using plain old vim as always, but eventually it became so unmanageable with files all over the place that I had to find a more manageable tool. I went with vscode, and I'm glad I did because vscode is incredibly well made. And the c/c++ extension is so good. It apparently makes an AST for my code on the fly and checks for all kinds of errors. I had never before used these sophisticated tools for writing C++. I generally used vanilla sublime with vim extention, or just command line vim. But really it's so nice. It's like discovering geysers for the first time when you've been showering with cold water all your life (strangely specific metaphor? sorry).
When writing the compiler, I used many new C++17 features. I was drawn into modern C++ first because of constexpr which allows you to make functions that are evaluated at compile time. I wanted to build a fast but manageable lexical analyser using a composition of constexpr functions but I realised that I was trying to prematurely optimize again, so I controlled myself. Maybe in version 0.2.
I also used C++17 lambda functions to declare nested functions to eliminate repeated actions that are only relevant inside a specific function. Here's an example:
auto makeDeclNode = [&](ast::astType a) {
stmt.reset(new ast::Ast);
astNode declaration;
if (declaration = declList()) {
stmt->type = a;
stmt->left = std::move(declaration);
} else
errQuit("declarations");
};
if (accept(lexer::tokenType::_int)) {
makeDeclNode(ast::astType::_intDecl);
} else if (accept(lexer::tokenType::_str)) {
makeDeclNode(ast::astType::_strDecl);
} else if (accept(lexer::tokenType::_bool)) {
makeDeclNode(ast::astType::_boolDecl);
}Maybe it's because I've coding a lot in javascript these days, but nested functions feel like an important language feature to have. मनसा has nested function support too.
I also tried to use C++ smart pointers everywhere. They make memory management so pleasant and take away most of the issues I used to deal when using raw pointers. But I did find the lack of good observer pointer idiom annoying and dangerous. Maybe they'll make it better by C++20, but hopefully I'll already be using Rust by then.
In v0.1, I have only implemented the lexer, parser, semantic analyzer and a rudimentary code generator with emits C++ code. In the new versions, I will progressively add new modules like optimizer, and redo some old ones.
- The Lexical Analyser is a simple finite state machine which iterates over each each UTF8 encoded character and converts them into tokens. I learnt a lot about Unicode while making the lexer. I am interested in world languages and scripts, so reading the Unicode documentation and other articles was fascinating to me. If you're interested in languages too, I cannot recommend at least skimming through the Unicode Standard enough. If you're in love with writing scripts like I am, do read this article on Smashing Magazine. I have written about Unicode in another blog post so maybe also check that out.The encoding of Unicode characters is also a fascinating topic. I find UTF-8 particularly beautiful. And as it turns out, it was designed by Ken and Rob from Bell Labs. I'm a big fan of the Bell Labs people.
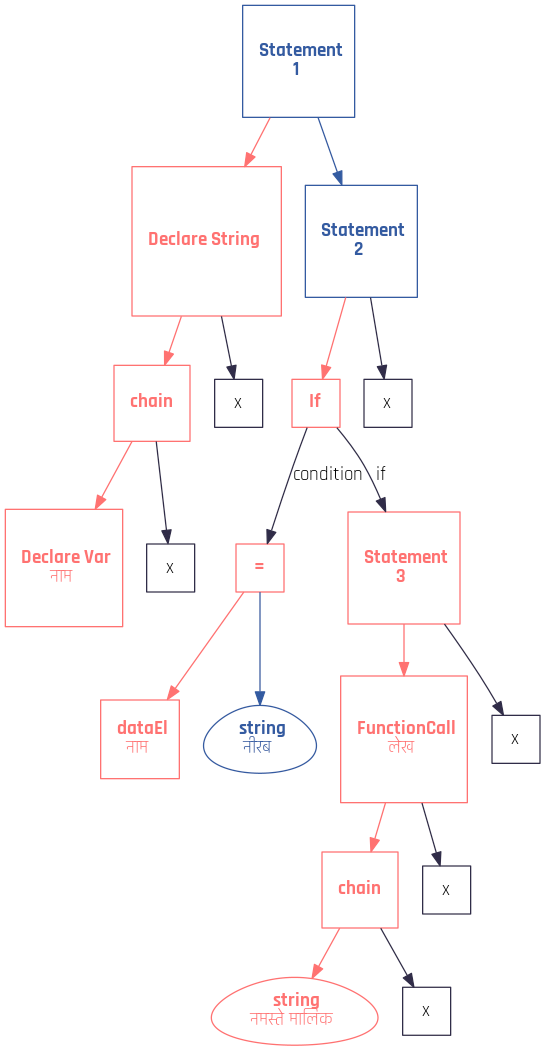
- I wrote the Parser using the Recursive Descent algorithm. It's crazy how simple yet powerful Recursive Descent is. I learnt it using only the Wikipedia article, wrote my first parser in a weekend, and it works like magic. It's just so elegant. In the current code base, the parser takes up the most volume at about a thousand lines. But I do believe that I should have mixed in some Pratt parsing to parse the operators, because recursive descent has to make a lot of function calls even for trivial tasks, which makes it inefficient. Oh well, maybe next time.The Parser makes an AST. Because the AST is vital, I wrote some routines to generate actual pictures from the AST. I've detailed the process in another blog post but this is what the AST's visualization looks like:
- The Semantic Analyser is all about recursively getting to all nodes in the AST and checking their types and making sure everything is according to rules.
- I had to write my own Symbol Table, which was awesome because I got to play with STL containers like pairs and unordered maps. Once you discover these tools, you can never go back to hand-coding data structures (which I'll admit was stupid, but I'm slowly fighting my not-invented-here syndrome).
- The actual Code Generator is not done yet. In it's place is a simple function which recursively navigates the AST and generates C++ code. For variable names, I just base64 encoded all Devanagari identifiers and replaced the illegal characters in base64 with underscore. The generated code looks like this:
int main(){
auto v4KSo4KSv4KS_pX_pCksuCkvuCkh_pCkqATT1 = [&]() {
cout << "\n";
};
int v4KSG4KSH = 100;
string v4KSV4KWB4KSw4KS_p = "नमस्ते";
while (v4KSG4KSH > 0) {
cout << v4KSV4KWB4KSw4KS_p;
v4KSo4KSv4KS_pX_pCksuCkvuCkh_pCkqATT1();
v4KSG4KSH= (v4KSG4KSH - 10) ;
};
}The Website
Making the website was like a pleasant stroll in the morning sun. It was not particularly challenging. I used Adobe XD to make a prototype and then designed it with vanilla CSS. I decided that unless there's an online compiler a website for a programming language is no use. I also fell in love with Haskell's online shell. But making it was going to be difficult.
I used vanilla javascript, socket.io library and Codemirror to make the compiler part. Learning to write the syntax highlighting was somewhat complicated so I just modified a preexisting one. I wanted anybody with a computer or a mobile phone to be able to go in, type code and try it out. So I also made an in-browser keyboard layout switcher which reads input keys and converts them to Nepali based on this keyboard layout, which we also made. I have yet to make the keyboard work on the phone, but I'm so busy these days that I don't yet have the time.

I apologize for the low quality GIF. I had to run the screen recording through so many online converters that all compressed the original in some form or another that now it looks like it came straight from early 2000s.
The backend part is also interesting, but it still needs lots of work. I basically instantiated a linux server on Azure and ran a simple NodeJS program on it which listens to socket.io requests for programs in मनसा, compiles the program, runs it in a sandbox, and pipes the input and output to the web terminal. I have put some primitive rate limiting and protections in the code but at some point I intend to use recaptcha or something to that effect to guard the API. I might also look to use cloud functions instead of running a full linux box all the time. I wrote a blog post documenting a part of the process here.
The IDE
I've hated ElectronJS with a passion I only reserve for a few things in life (like the Cursed Child) The hate is a result of a few factors. I use a 6 year old Dell laptop as my computer which is so dilapidated at this point that it stutters when I have lots of chrome tabs and VScode running at the same time. So I appreciate parsimony from the developer's side. I'm also kind of annoyed at this developer-first culture we developers are promoting, piggybacking simply on the fact that computers are getting faster and with more memory than before.
But then the night before a major demonstration of the project I was in such a rush because I had so many things to make and refine, that I broke all my rules and made a deal with the devil itself. Oh mighty devil, oh accomplice of the photon, oh sinful chimera of chromium and nodejs, oh gods of chaos and asynchronicity, I implore you.
Anyway, the results were astounding. In about three hours, I had a perfectly working syntax-highlighting enabled (thanks again, CodeMirror), beautiful IDE for demonstration. It could compile and run the code and upload it to Arduino too (with some avrdude magic, of course). ElectronJS is incredibly fast and simple (for the developer, at least). Even though the reasons for hating ElectronJS are still valid, I got a new perspective by actually working on it, and I've added it into my toolbox. Thank you, ElectronJS, for taking me back to my childhood days of Visual Basic and RAD.
The Arduino interface
मनसा can also write code for Arduino. The idea came when I was trying to teach my cousin (who's 12) this programming language. I realized that it's difficult to get a kid to relate to the world inside the computer. For example, when teaching the concept of looping for the first time, it's way easier to show him a led blinking 10 times and explain the code than to show him ten instances of 'Hello World'.
So I added in some features to the language, mainly the external mechanism which allows you to write C code inside मनसा functions. The resulting system is kind of hacky but surprisingly flexible. The embedded C code does most of the register twiddling and bit flipping, and exposes high level functions to मनसा. That code is written as library. Then, using the import mechanism of the language, you can import these functions and access them like normal मनसा functions. I will put in a video demonstration when I have the time.
Random, interesting observations
- It's nice to have a small code diary, if you will, to jot down all complex ideas that you think up while coding. I made a
diary.mdfile on the root of the source tree to keep a chronological log of my thoughts, snippets of codes, things I had to do next, of bugs and other things in the file. - C++11 range based loops are awesome. I know about these before.
- Makefiles get very sloppy very fast and annoying to maintain. I must learn to use more sophisticated build system soon. Maybe Cmake? The build system should be able to build on both Linux and on WSL, install all required programs if they don't exist, and only compile the libraries that actually changed.
- Most of the 3000+ lines of code I've written is worthless. I read somewhere lines of code are not investments, rather they are loans. The more you add to the codebase, the more expensive you make it to maintain it. It takes more time for a prospective contributor to make sense of the whole project. The more lines you write, the more bugs you hide. I would have been far far better using a parser generator and making the language interpreted instead of compiled. That would reduce complexity of the system and let me focus on the big picture and on the applications of the language.
- At some point, you really need a second, vertical monitor.
- Compiling larger code bases takes far more time than you expect.


